Finetuning Ninja : Semaine 1 - Le Lab
Session 1 : Stratégies Modernes de Pré-entraînement – Guide Pratique
Après avoir posé les bases théoriques des Transformers et du pré-entraînement dans la leçon précédente, il est temps de passer à la pratique ! Ce premier laboratoire (Lab) plonge au cœur des stratégies modernes pour adapter un modèle à un domaine spécifique et aborde les défis matériels cruciaux liés à l’entraînement des LLMs.
1. Le “Continued PreTraining” (CPT) : Apprendre un Nouveau Domaine
Que faire si vous avez besoin d’un modèle expert en droit, en médecine ou sur une base de code très spécifique ? Le pré-entraînement classique sur des données générales d’Internet (qui survole de nombreux sujets de manière superficielle) ne suffit pas. C’est là qu’intervient le Continued PreTraining (CPT).
⚠️ Attention à la nuance fondamentale : le CPT n’est pas du Supervised Fine-Tuning (SFT) ! * Dans le SFT, on fournit des paires “prompt-réponse” pour apprendre au modèle à se comporter et à interagir. * Dans le CPT, on retourne à l’apprentissage auto-supervisé. On nourrit le modèle avec des textes bruts et non labellisés (par exemple, 50 Go de documents internes ou de publications mathématiques) avec l’objectif de “prédire le token suivant”.
Pourquoi cette étape est-elle cruciale ? 1. Vocabulaire du domaine : Le modèle apprend des termes très spécialisés et leurs contextes, souvent absents du pré-entraînement initial. 2. Mise à jour des connaissances (World Knowledge) : C’est le moyen de mettre à jour un modèle (ex: lui apprendre les découvertes de 2025 s’il a été entraîné en 2023). 3. Une meilleure fondation pour le SFT : Si le modèle de base ne comprend pas intrinsèquement les concepts d’un domaine, tenter de le finetuner (SFT) sur des instructions de ce domaine entraînera inévitablement de fortes hallucinations.
2. L’Apprentissage Curriculaire (Curriculum Learning)
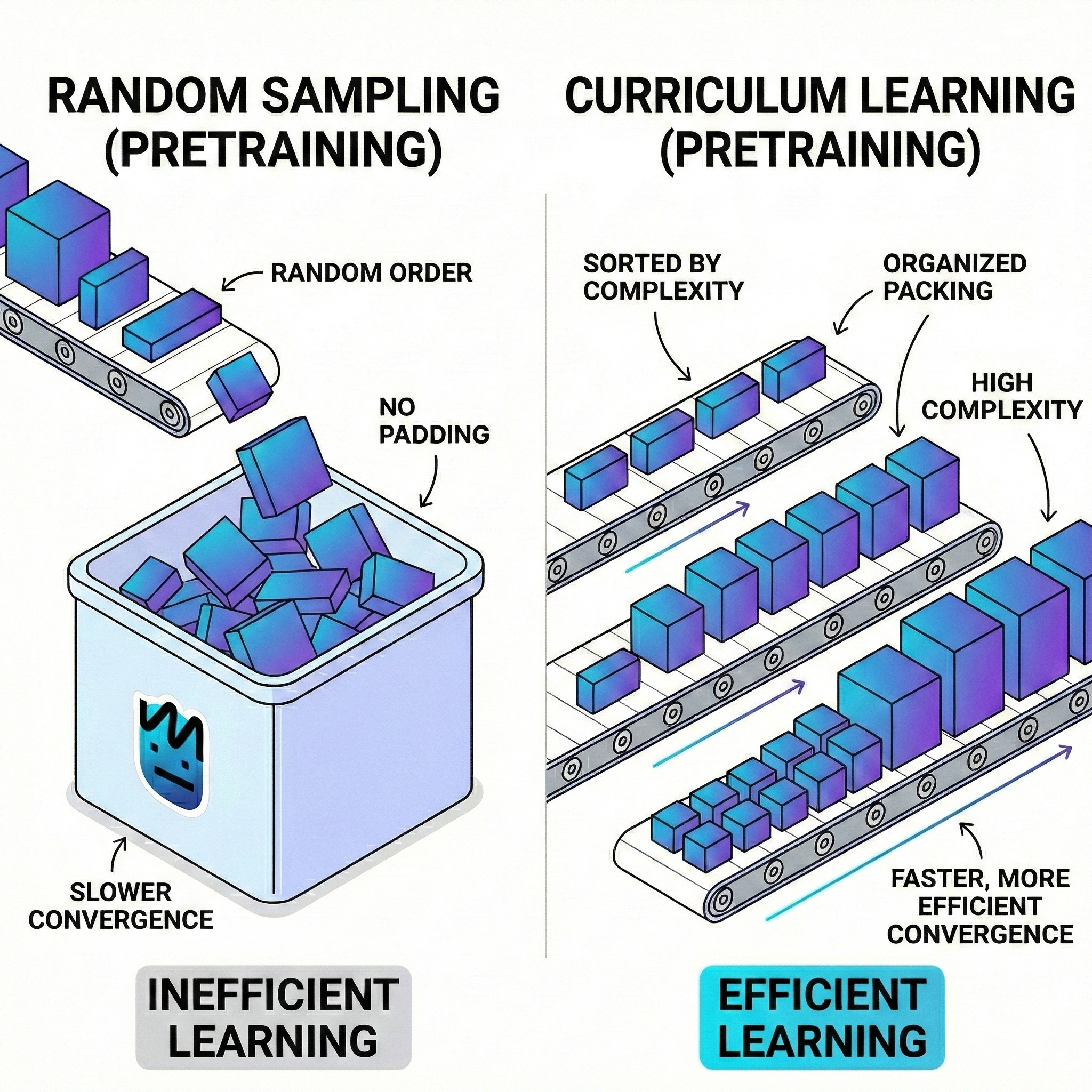
Adapter un modèle (surtout un Small Language Model, ou SLM) à un domaine rigoureux comme les mathématiques n’est pas aussi simple que de lui “jeter” un manuel entier. Si l’on donne immédiatement des données trop complexes, le modèle sature : ses gradients deviennent instables et il peine à converger.
La solution est le Curriculum Learning, inspiré de l’éducation humaine : on n’enseigne pas le calcul intégral à un enfant avant qu’il sache additionner. On organise les données par complexité ou par ratio signal/bruit.
Deux méthodes courantes d’implémentation : 1. Tri par qualité des données (Data Quality Sorting) : Commencer par des données “Gold Standard” (Wikipedia, manuels de base) avant d’introduire des données plus denses ou plus bruitées (Reddit, web crawl). 2. Mise à l’échelle de la longueur de séquence (Sequence Length Scaling) : Démarrer avec une petite fenêtre de contexte (ex: 512 tokens) pour assimiler la syntaxe locale, puis augmenter progressivement (4k, 8k, etc.) pour capter les dépendances à long terme.
Résultat : Une convergence plus rapide, une perte (loss) finale plus basse, et un modèle beaucoup plus robuste.
3. La Distillation de Connaissances (Knowledge Distillation)
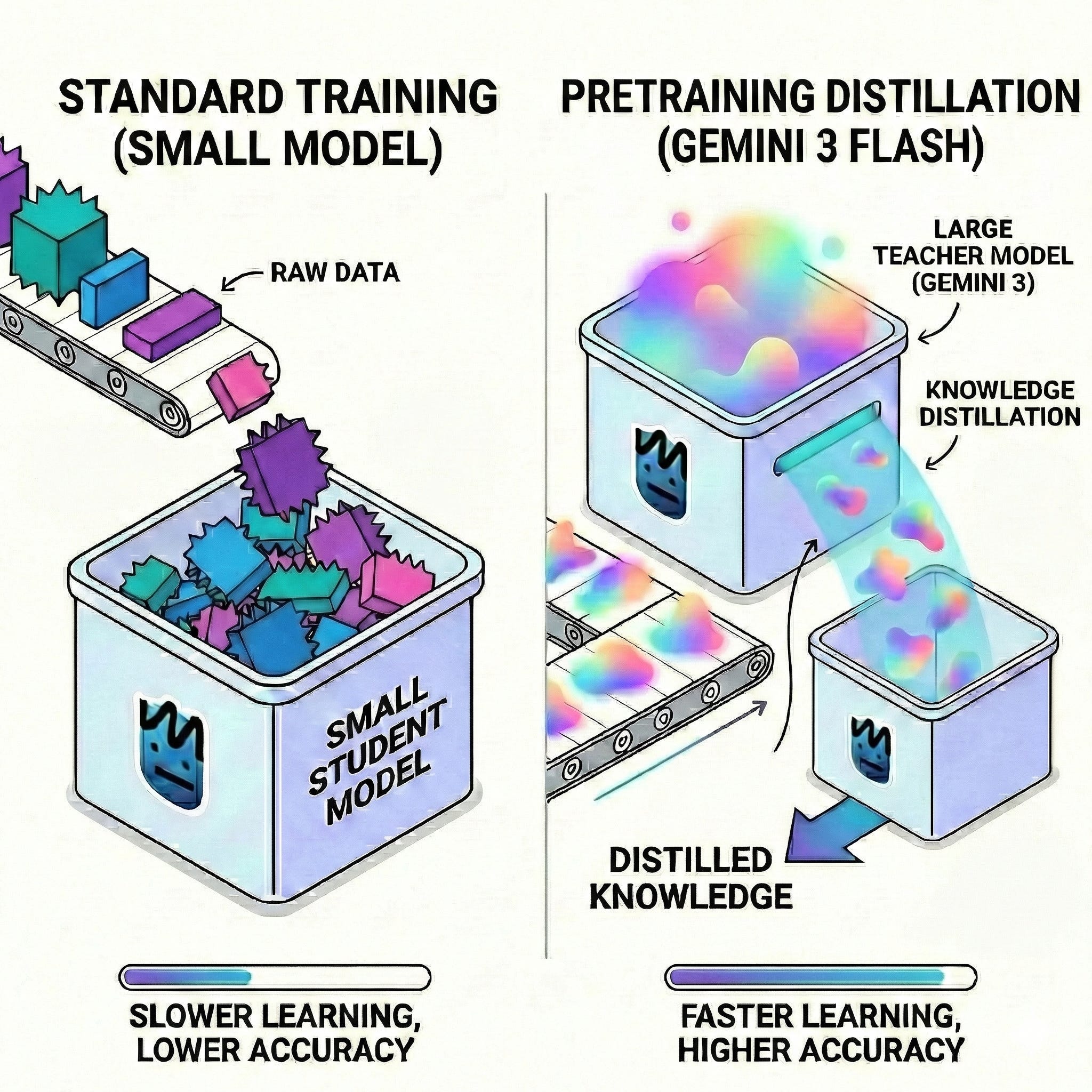
Comment un “petit” modèle de 7 milliards de paramètres peut-il parfois battre un géant de 70B ? Grâce à la distillation.
L’idée : utiliser l’intelligence d’un modèle “Professeur” (Teacher) massif (comme GPT-4) pour entraîner un petit modèle “Élève” (Student). Plutôt que d’utiliser des labels stricts (ex: “le mot suivant est Paris”), l’Élève apprend à partir des “Soft Targets” du Professeur. Le Professeur fournit une distribution de probabilités : “Je suis sûr à 90% que c’est Paris, 8% Lyon, 2% Londres”.
Cette information (souvent appelée “Dark Knowledge”) révèle comment le Professeur perçoit les relations sémantiques. * Efficacité : On obtient un modèle 10x plus petit et rapide, conservant une grande partie des capacités du Professeur. * Transfert de raisonnement : Via la distillation “Chain-of-Thought” (CoT), l’Élève peut même apprendre le processus de réflexion étape par étape du Professeur.
4. Dompter le “Mur de la Mémoire” (Hardware & Optimisation)
L’entraînement coûte cher en ressources. Une erreur de débutant est de penser qu’un modèle de 14 Go rentrera dans un GPU de 16 Go. C’est faux ! Pendant l’entraînement, il faut stocker les poids, mais aussi les activations, les gradients et surtout les états de l’optimiseur (qui peuvent représenter 3 à 4 fois la taille des poids !).
Les techniques d’optimisation (Tricks) : * Mixed Precision (BF16) : Le “Brain Float 16” offre la plage dynamique d’un format 32-bits mais avec l’empreinte mémoire d’un 16-bits. Il accélère l’entraînement sans l’instabilité du FP16 classique. * Gradient Accumulation : Si la mémoire du GPU est trop petite pour un grand batch, on calcule les gradients sur des “micro-batchs” et on ne met à jour les poids qu’après plusieurs étapes. * Activation Checkpointing : Plutôt que de stocker toutes les activations (pensées intermédiaires) lors de la passe avant (forward pass), on les supprime de la mémoire et on les recalcule lors de la passe arrière (backward pass). Compromis : on économise énormément de VRAM au prix d’environ 25% de temps de calcul supplémentaire.
(Astuce : Si la mémoire GPU est pleine mais que l’utilisation de calcul (SM) est faible, le goulot d’étranglement est votre CPU ou votre chargeur de données, pas le GPU !)
5. L’Orchestre Multi-GPU (Parallélisme)
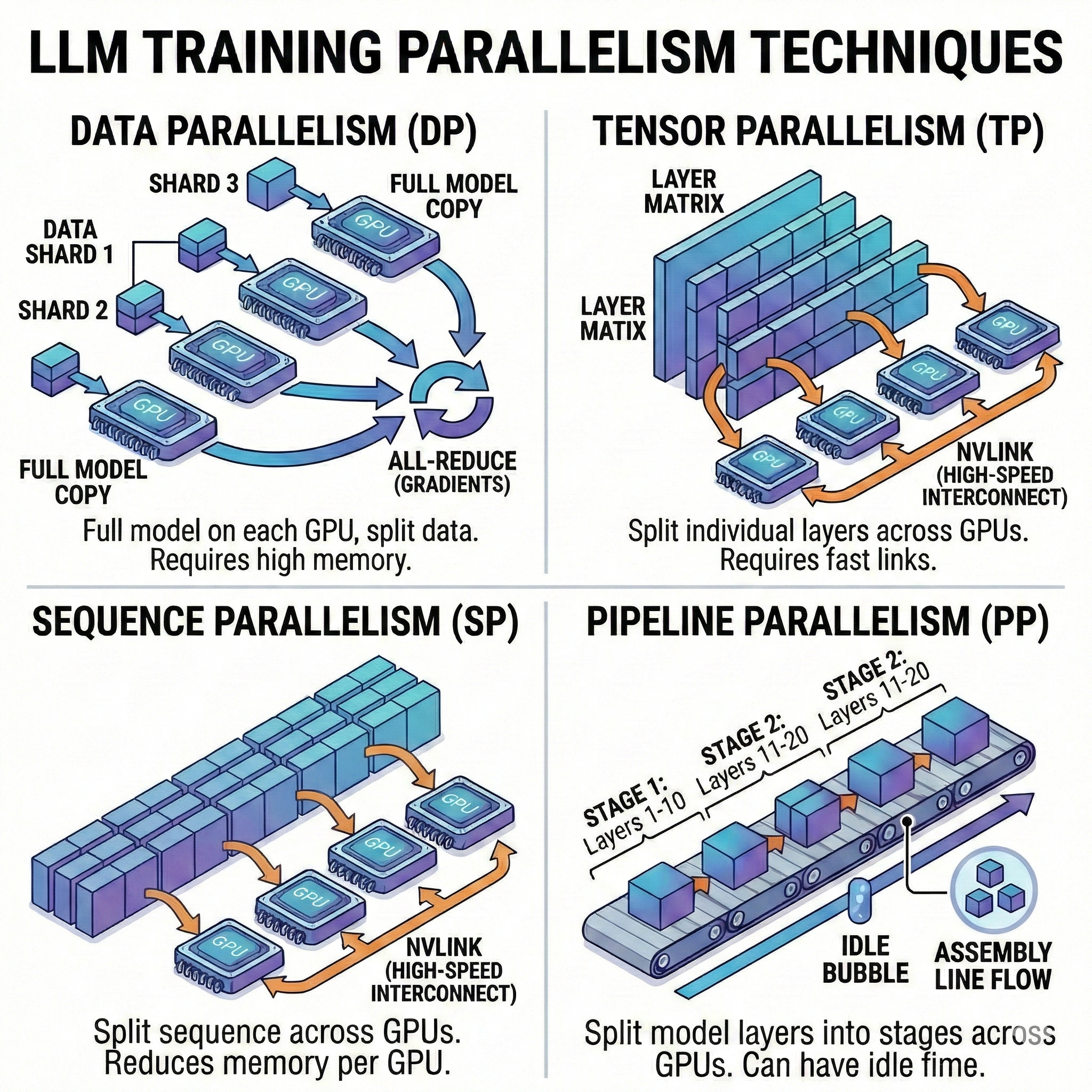
Pour les très gros modèles, un seul GPU ne suffit pas. Il faut diviser le travail : 1. Data Parallelism (DP/DDP) : Le modèle entier est copié sur chaque GPU, mais chaque GPU traite un sous-ensemble différent des données. 2. Tensor Parallelism (TP) : On divise littéralement les matrices de poids d’une même couche sur plusieurs GPUs. Nécessite des connexions ultra-rapides (NVLink). 3. Pipeline Parallelism (PP) : Division verticale par couches (ex: GPU 0 gère les couches 1-10, GPU 1 les couches 11-20). Le défi est de minimiser les temps d’inactivité (“bubbles”). 4. Sequence Parallelism (SP) : Indispensable pour traiter des contextes extrêmement longs qui feraient exploser la mémoire.
Le Standard Moderne : FSDP (Fully Sharded Data Parallelism). C’est une approche hybride qui fragmente (shard) les poids, les gradients et les états de l’optimiseur sur tous les GPUs, offrant l’efficacité mémoire du parallélisme de modèle avec la simplicité du parallélisme de données.
🎯 Quiz d’Auto-Évaluation : Testez vos connaissances
Voici 5 questions pour valider votre assimilation des concepts de ce Lab :
Question 1 : Quelle est la différence fondamentale dans l’objectif d’entraînement entre le Continued PreTraining (CPT) et le Supervised Fine-Tuning (SFT) ?
Le CPT utilise l’apprentissage auto-supervisé sur des textes bruts (non labellisés) avec l’objectif de “prédire le token suivant”, exactement comme lors du pré-entraînement initial. Le SFT, en revanche, utilise des paires “prompt-réponse” structurées pour apprendre au modèle à suivre des instructions spécifiques et à formater ses réponses.
Question 2 : Pourquoi est-il déconseillé de fournir immédiatement des données extrêmement complexes à un modèle lors du Continued PreTraining, et quelle technique permet d’éviter ce problème ?
Fournir des données trop denses ou bruitées d’emblée peut provoquer une “saturation” du modèle et rendre ses gradients instables (il peine à converger ou apprend de mauvais motifs). La technique pour éviter cela est le Curriculum Learning (Apprentissage Curriculaire), qui consiste à ordonner les données de la plus simple/propre à la plus complexe, permettant aux poids du modèle de se configurer de manière plus robuste.
Question 3 : Dans la distillation de connaissances (Knowledge Distillation), pourquoi les “Soft Targets” du modèle Professeur sont-elles plus utiles que des labels classiques (Hard Labels) ?
Les Soft Targets fournissent une distribution de probabilités pour l’ensemble du vocabulaire, et non pas une seule réponse “correcte”. Cette distribution (le “Dark Knowledge”) contient des informations cruciales sur la façon dont le Professeur perçoit les relations sémantiques entre les mots (ex: savoir qu’une mauvaise réponse est tout de même sémantiquement proche de la bonne réponse), ce qui aide l’Élève à généraliser bien plus efficacement.
Question 4 : Quel compromis technique offre l’“Activation Checkpointing” lors de l’entraînement d’un modèle pour éviter l’erreur “Out Of Memory” (OOM) ?
L’Activation Checkpointing permet d’économiser massivement de la VRAM (mémoire GPU) en supprimant de la mémoire les activations intermédiaires calculées lors de la passe avant (forward pass). Le compromis est que ces activations doivent être recalculées lors de la passe arrière (backward pass), ce qui augmente le temps de calcul (compute) d’environ 25%. On échange donc du temps de calcul contre de l’espace mémoire.
Question 5 : Pourquoi le “Data Parallelism” classique (DP) n’est-il plus suffisant pour les modèles géants actuels, et pourquoi utilise-t-on le FSDP ?
Le Data Parallelism (DP) copie l’intégralité du modèle sur chaque GPU. Pour les modèles géants (comme un 70B), même un seul modèle avec ses états d’optimisation dépasse la capacité d’un GPU haut de gamme (comme un H100 de 80 Go). Le FSDP (Fully Sharded Data Parallelism) résout ce problème en fragmentant (sharding) les poids du modèle, les gradients et les états de l’optimiseur à travers tous les GPUs disponibles, combinant l’efficacité mémoire du parallélisme de modèle avec la simplicité de gestion du parallélisme de données.