Finetuning Ninja : Semaine 1 - Le Paysage
Leçon 1 : Cartographie de l’Entraînement des LLMs Modernes
Bienvenue dans cette première semaine de notre Bootcamp dédié au Finetuning ! Petit retournement de situation pour commencer : nous n’allons pas du tout parler de finetuning aujourd’hui.
Avant de plonger dans des techniques avancées comme le SFT (Supervised Fine-Tuning) ou LoRA, il est crucial de bâtir une carte mentale solide de ce qui se passe avant cette étape. Cette leçon pose les fondations de l’architecture Transformer et du pré-entraînement (pretraining), car comprendre le fonctionnement interne des modèles est essentiel pour maîtriser les techniques d’optimisation futures.
1. L’Évolution : Des RNNs à l’Attention

Aujourd’hui, presque tous les modèles de langage de pointe (LLMs) reposent sur l’architecture Transformer. Mais l’innovation clé qui les fait fonctionner – le mécanisme d’attention – n’a pas été inventée avec le Transformer.
Avant cela, le Deep Learning s’appuyait sur les CNNs pour la vision et les RNNs (notamment les LSTMs) pour les tâches séquentielles comme la traduction. Le problème des RNNs ? Ils peinaient avec les longues séquences car ils devaient compresser toute la phrase d’entrée en un seul vecteur de taille fixe.
L’attention a été introduite pour résoudre ce problème : et si le modèle pouvait “regarder en arrière” vers différentes parties spécifiques de l’entrée au moment où il en a besoin ?.

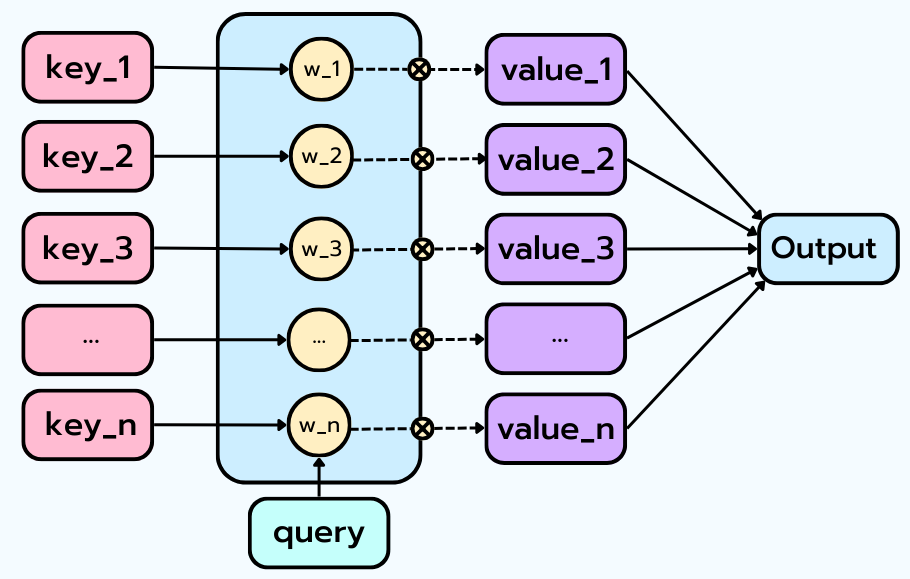
Comment fonctionne l’Attention ? À la base, l’attention est un mécanisme de recherche pondérée qui utilise trois éléments :
* Des Keys (Clés - K)
* Des Values (Valeurs - V)
* Une Query (Requête - Q)
Le mécanisme compare la requête (Q) à toutes les clés (K), attribue un poids à chacune (un score d’importance), puis produit une somme pondérée des valeurs (V). L’attention décide ainsi de ce qui est important dans le contexte et le combine dynamiquement.
2. Le Cœur du Transformer : Self-Attention et Multi-Head Attention
Si l’attention permettait à un décodeur de regarder un encodeur, la Self-Attention (Auto-attention) va plus loin : chaque token d’une séquence porte son attention sur tous les autres tokens de cette même séquence.
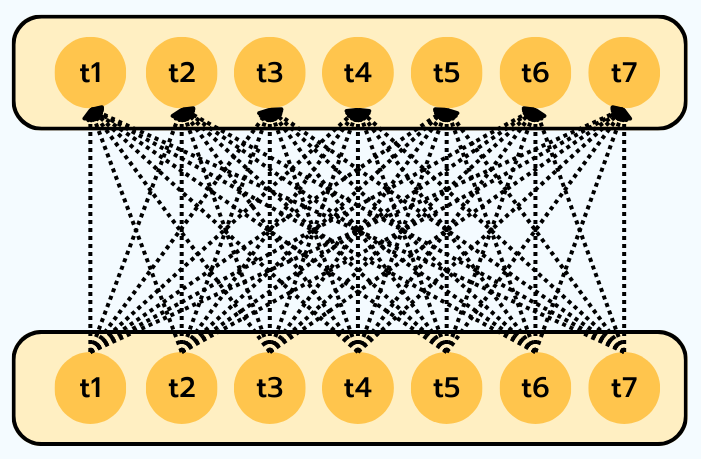
Dans la self-attention, chaque token devient à la fois Q, K et V. Par exemple, pour mettre à jour la représentation du mot “sat” (assis), le modèle portera une forte attention sur “cat” (le chat) et “mat” (le tapis), tout en ignorant les mots de liaison moins pertinents comme “the”.
Pour faire fonctionner cela, l’architecture Transformer introduit des composants spécifiques :
1. Positional Encodings (Encodages de position) : L’attention n’a pas de notion d’ordre spatial ou temporel. On injecte donc des informations de position via des fonctions mathématiques (sinus et cosinus à différentes fréquences) pour que le modèle distingue le premier, le suivant ou le dernier token.
2. Scaled Dot-Product Attention : C’est l’implémentation mathématique où les Queries et les Keys sont multipliées (dot product), normalisées par une fonction softmax, puis utilisées pour calculer une somme pondérée des Values.
3. Multi-Head Attention : Au lieu d’avoir un seul point de vue, le modèle utilise “plusieurs têtes” travaillant en parallèle. Différentes têtes se spécialisent dans divers motifs (dépendances à long terme, syntaxe, sémantique), permettant au modèle d’examiner l’information sous plusieurs angles simultanément.
3. Les Trois Architectures de Transformers
Bien que l’on regroupe souvent tout sous le terme de LLM, il existe trois familles distinctes de Transformers, chacune conçue pour des problèmes différents :
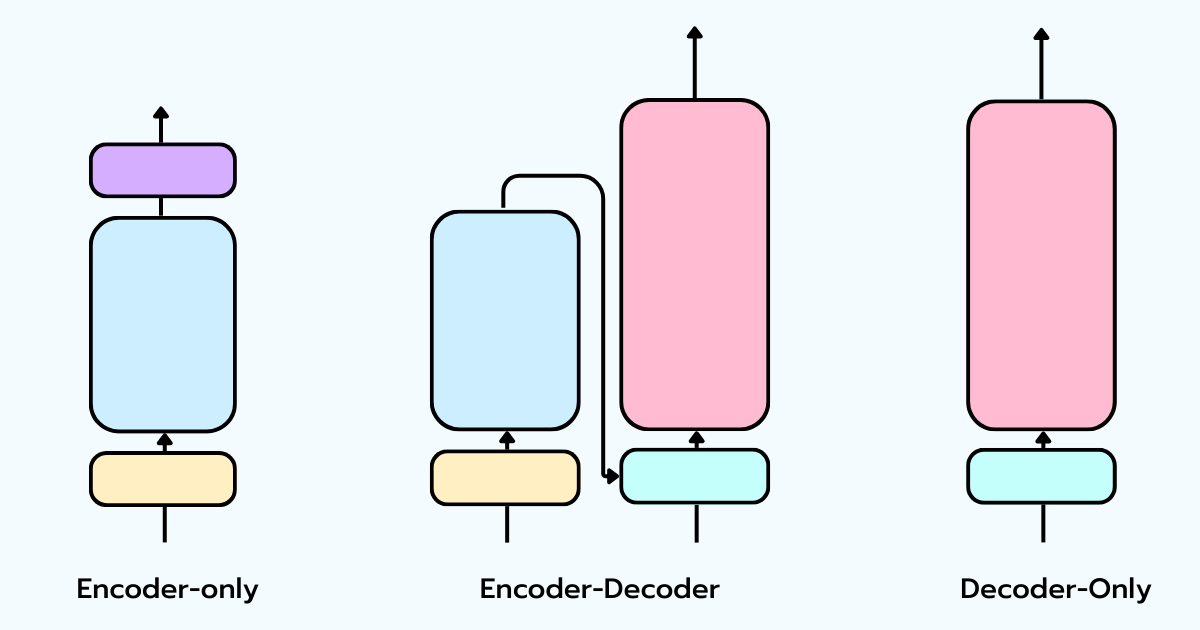
- Encoder-only (ex: BERT) : Conçu pour générer des représentations riches. Il utilise une attention bidirectionnelle (les tokens regardent en avant et en arrière). Parfait pour la classification, la similarité sémantique et la recherche, mais il ne génère pas de texte.
- Encoder-Decoder (ex: T5, BART) : L’architecture originale. L’encodeur lit l’entrée, et le décodeur génère la sortie token par token en utilisant l’attention croisée (cross-attention). Idéal pour les tâches où l’entrée et la sortie sont des séquences de longueur variable comme la traduction.
- Decoder-only (ex: ChatGPT, Claude, Qwen) : C’est le moteur de presque tous les LLMs modernes. Il supprime complètement l’encodeur et utilise l’attention causale : chaque token ne peut regarder que les tokens qui le précèdent. Son seul objectif est de prédire le token suivant.
Le succès foudroyant de l’architecture “Decoder-only” s’explique en grande partie par les lois d’échelle (Scaling laws). Des études ont montré que la performance de ces modèles s’améliore de façon prévisible lorsque l’on augmente la taille du modèle (paramètres), les données d’entraînement (tokens) et la puissance de calcul.
4. Le Pipeline d’Entraînement des LLMs et le Pretraining
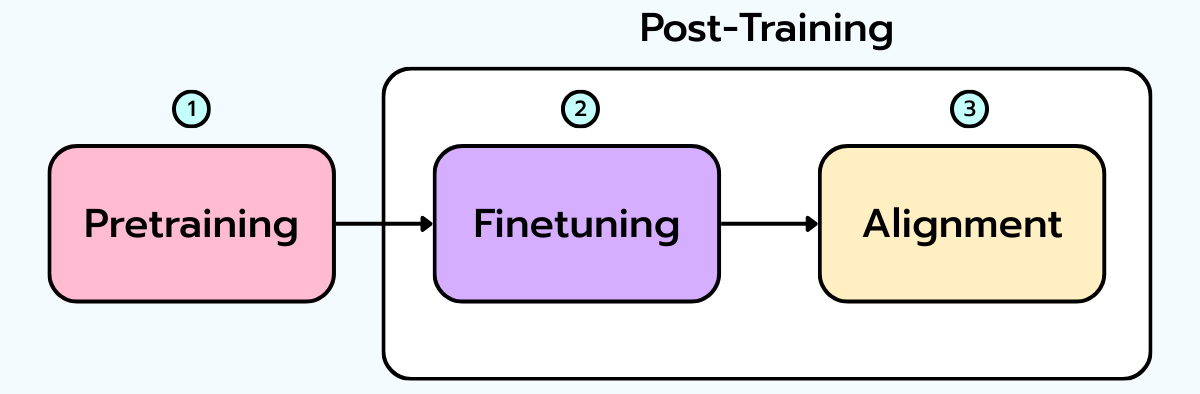
Depuis l’introduction du modèle InstructGPT d’OpenAI en 2022, la norme d’entraînement d’un LLM (Decoder-only) suit un pipeline bien défini en trois étapes :
1. Pretraining (Pré-entraînement sur de vastes corpus de textes bruts).
2. Supervised Fine-Tuning - SFT (Affinement supervisé sur des exemples de haute qualité orientés vers des tâches).
3. RLHF - Reinforcement Learning from Human Feedback (Alignement basé sur les préférences humaines).
Zoom sur le Pretraining : C’est l’étape la plus gourmande en données et en calcul. Un modèle Transformer “Decoder-only” s’entraîne via un apprentissage auto-supervisé : le label à prédire est simplement le token suivant dans le texte (Causal Language Modeling).
En “lisant” des quantités massives de pages web, de livres et de code, le modèle acquiert la grammaire, la syntaxe, des faits et du sens commun. C’est la phase où il “apprend le monde”.
Le résultat est un “Modèle de Base” (Foundation Model). Mais attention : à ce stade, le modèle excelle pour continuer un texte, mais il ne sait pas répondre de manière fiable à des instructions ou interagir. C’est un moteur brut de reconnaissance de motifs. Le finetuning (SFT, LoRA) sert à façonner et orienter (shape and steer) l’intelligence brute acquise lors du pretraining pour la rendre utilisable et alignée sur nos attentes.
Le Continued Pretraining : Si vous devez ajouter un domaine très spécifique (droit, médical) ou une langue sous-représentée, on utilise le Continued Pretraining. Au lieu de tout recommencer de zéro, on expose un modèle de base existant à de nouvelles données pour qu’il absorbe ces nouveaux motifs tout en conservant ses connaissances générales.
🎯 Quiz d’Auto-Évaluation : Testez vos connaissances
Question 1 : Quel problème fondamental des réseaux de neurones récurrents (RNNs) le mécanisme d’attention original cherchait-il à résoudre ?
Les architectures récurrentes antérieures (comme les encodeurs-décodeurs basés sur les LSTMs) devaient compresser toute une séquence d’entrée en un seul vecteur de taille fixe. Cela limitait fortement leurs performances sur les longues séquences. L’attention a résolu ce problème en permettant au décodeur de regarder dynamiquement différentes parties de l’entrée au moment où il en a besoin, au lieu de s’appuyer sur un état compressé unique.
Question 2 : Quelle est la principale différence entre l’attention classique et la “Self-Attention” ?
L’attention classique permet à une séquence (le décodeur) de prêter attention à une autre séquence (l’encodeur). La “Self-Attention” (auto-attention) va plus loin : elle permet à chaque token d’une séquence de prêter attention à tous les autres tokens de cette même séquence. Ainsi, les requêtes (Q), les clés (K) et les valeurs (V) proviennent toutes de la même source.
Question 3 : Pourquoi l’architecture Transformer nécessite-t-elle l’utilisation d’encodages de position (Positional Encodings) ?
Le mécanisme d’attention en lui-même n’a aucune notion de l’ordre des éléments dans une séquence. Contrairement aux RNNs qui traitent les données séquentiellement, les Transformers traitent les tokens en parallèle. Les encodages de position (basés sur des fonctions sinus et cosinus) injectent artificiellement des informations spatiales dans les représentations des tokens pour que le modèle puisse distinguer le “premier”, le “suivant” et le “dernier” élément.
Question 4 : Parmi les trois familles d’architectures Transformer, laquelle est utilisée par des modèles comme ChatGPT et Claude, et quel est son objectif d’entraînement principal ?
Ces modèles utilisent l’architecture Decoder-only (décodeur uniquement). Son objectif d’entraînement principal, via une attention causale (qui empêche de regarder les tokens futurs), est extrêmement simple : prédire le token suivant (Causal Language Modeling).
Question 5 : Quel est l’objectif du Supervised Fine-Tuning (SFT) et du RLHF si le modèle a déjà appris le langage lors du pretraining ?
Le pretraining produit un “modèle de base” capable de générer du texte de manière très crédible et possédant une grande connaissance du monde, mais il se contente de continuer le texte sans savoir répondre à des instructions ou être utile. Le SFT et le RLHF servent à façonner et orienter cette intelligence brute. Ils apprennent au modèle comment structurer ses réponses, suivre des consignes, et se comporter selon les attentes et la sécurité humaines, sans avoir à lui réapprendre le langage depuis zéro.
Question 6 : Quel est le rôle des composantes “Query”, “Key” et “Value” ?
C’est une métaphore de recherche. La Query représente ce que je cherche, la Key est l’étiquette de l’information disponible, et la Value est l’information elle-même. Le score d’attention (Query x Key) détermine combien de “poids” on donne à chaque “Value”.
Question 7 : Pourquoi les modèles modernes comme Llama ou GPT utilisent-ils principalement l’architecture “Decoder-only” ?
Cette architecture est plus simple à passer à l’échelle (scaling). Elle s’est avérée incroyablement efficace pour l’apprentissage auto-supervisé sur d’immenses volumes de données, et elle possède des capacités émergentes (raisonnement, calcul) que les autres architectures n’atteignent pas aussi facilement.
Question 8 : Dans quel cas utiliseriez-vous le “Continued Pretraining” au lieu du simple Fine-tuning ?
On utilise le pré-entraînement continu quand on veut injecter des connaissances massives dans un domaine très spécifique (ex : droit médical complexe, langage de programmation rare ou langue peu représentée) que le modèle n’a jamais vu, avant de lui apprendre à suivre des instructions dans ce domaine.