Finetuning Ninja: Week 1 - The Lab
Session 1: Modern Pre-training Strategies – Practical Guide
After laying the theoretical foundations of Transformers and pre-training in the previous lesson, it’s time for some hands-on practice! This first laboratory (Lab) dives into modern strategies for adapting a model to a specific domain and addresses the crucial hardware challenges associated with training LLMs.
1. “Continued PreTraining” (CPT): Learning a New Domain
What if you need a model that is an expert in law, medicine, or a very specific codebase? Classic pre-training on general internet data (which skims over many topics superficially) is not enough. This is where Continued PreTraining (CPT) comes in.
⚠️ Note the fundamental nuance: CPT is not Supervised Fine-Tuning (SFT)! * In SFT, we provide “prompt-response” pairs to teach the model how to behave and interact. * In CPT, we go back to self-supervised learning. We feed the model raw, unlabeled text (e.g., 50GB of internal documents or math publications) with the objective of “predicting the next token.”
Why is this step crucial? 1. Domain Vocabulary: The model learns highly specialized terms and their contexts, often missing from the initial pre-training. 2. Updating Knowledge (World Knowledge): It’s the way to update a model (e.g., teaching it 2025 discoveries if it was trained in 2023). 3. A Better Foundation for SFT: If the base model doesn’t intrinsically understand the concepts of a domain, attempting to finetune (SFT) it on instructions from that domain will inevitably lead to severe hallucinations.
2. Curriculum Learning
Adapting a model (especially a Small Language Model, or SLM) to a rigorous domain like mathematics is not as simple as “throwing” an entire manual at it. If you immediately provide data that is too complex, the model saturates: its gradients become unstable and it struggles to converge.
The solution is Curriculum Learning, inspired by human education: we don’t teach integral calculus to a child before they know how to add. We organize data by complexity or signal-to-noise ratio.
Two common implementation methods: 1. Data Quality Sorting: Start with “Gold Standard” data (Wikipedia, basic textbooks) before introducing denser or noisier data (Reddit, web crawl). 2. Sequence Length Scaling: Start with a small context window (e.g., 512 tokens) to grasp local syntax, then gradually increase (4k, 8k, etc.) to capture long-term dependencies.
Result: Faster convergence, lower final loss, and a much more robust model.
3. Knowledge Distillation
How can a “small” model with 7 billion parameters sometimes beat a giant with 70B? Through distillation.
The idea: use the intelligence of a massive “Teacher” model (like GPT-4) to train a small “Student” model. Instead of using strict labels (e.g., “the next word is Paris”), the Student learns from the Teacher’s “Soft Targets.” The Teacher provides a probability distribution: “I’m 90% sure it’s Paris, 8% Lyon, 2% London.”
This information (often called “Dark Knowledge”) reveals how the Teacher perceives semantic relationships. * Efficiency: We get a model 10x smaller and faster, retaining much of the Teacher’s capabilities. * Reasoning Transfer: Through “Chain-of-Thought” (CoT) distillation, the Student can even learn the Teacher’s step-by-step thinking process.
4. Taming the “Memory Wall” (Hardware & Optimization)
Training is resource-intensive. A beginner mistake is thinking a 14GB model will fit in a 16GB GPU. It won’t! During training, you need to store weights, but also activations, gradients, and most importantly optimizer states (which can be 3-4 times the size of the weights!).
Optimization Techniques (Tricks): * Mixed Precision (BF16): “Brain Float 16” offers the dynamic range of a 32-bit format but with the memory footprint of 16-bit. It speeds up training without the instability of classic FP16. * Gradient Accumulation: If GPU memory is too small for a large batch, we calculate gradients on “micro-batches” and only update weights after several steps. * Activation Checkpointing: Instead of storing all activations (intermediate thoughts) during the forward pass, we delete them from memory and recalculate them during the backward pass. Trade-off: significant VRAM savings at the cost of about 25% extra compute time.
(Tip: If GPU memory is full but compute (SM) usage is low, the bottleneck is your CPU or data loader, not the GPU!)
5. The Multi-GPU Orchestra (Parallelism)
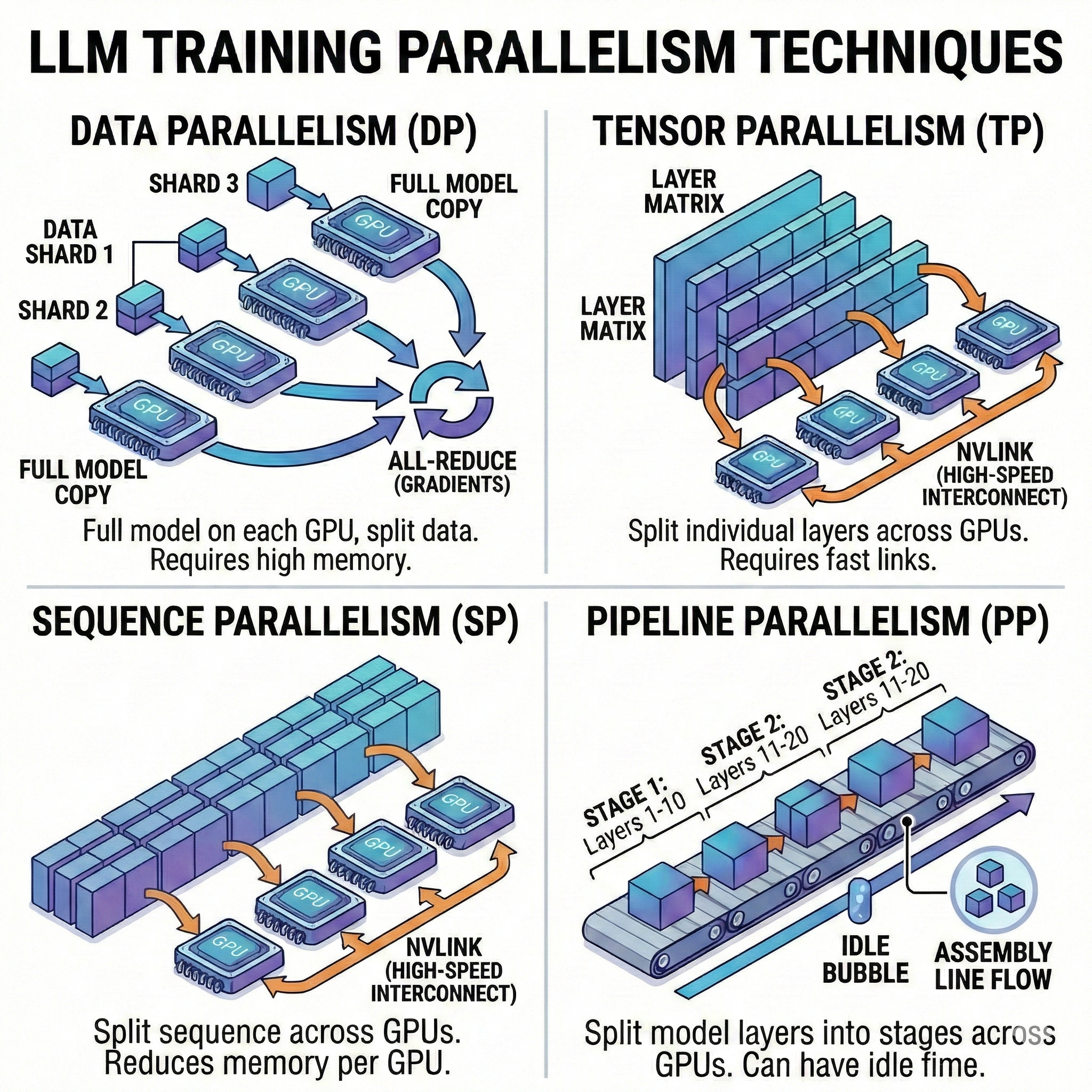
For very large models, a single GPU is not enough. You have to divide the work: 1. Data Parallelism (DP/DDP): The entire model is copied to each GPU, but each GPU processes a different subset of data. 2. Tensor Parallelism (TP): We literally split the weight matrices of a single layer across multiple GPUs. Requires ultra-fast connections (NVLink). 3. Pipeline Parallelism (PP): Vertical division by layers (e.g., GPU 0 handles layers 1-10, GPU 1 handles layers 11-20). The challenge is minimizing “bubbles” (idle time). 4. Sequence Parallelism (SP): Essential for processing extremely long contexts that would otherwise explode memory.
The Modern Standard: FSDP (Fully Sharded Data Parallelism). This is a hybrid approach that shards weights, gradients, and optimizer states across all GPUs, offering the memory efficiency of model parallelism with the simplicity of data parallelism.
🎯 Self-Assessment Quiz: Test Your Knowledge
Here are 5 questions to validate your understanding of the concepts in this Lab:
Question 1: What is the fundamental difference in training objectives between Continued PreTraining (CPT) and Supervised Fine-Tuning (SFT)?
CPT uses self-supervised learning on raw (unlabeled) text with the objective of “predicting the next token,” exactly like the initial pre-training. SFT, on the other hand, uses structured “prompt-response” pairs to teach the model how to follow specific instructions and format its responses.
Question 2: Why is it discouraged to immediately provide extremely complex data to a model during Continued PreTraining, and what technique avoids this problem?
Providing data that is too dense or noisy from the start can cause model “saturation” and make gradients unstable (struggling to converge or learning bad patterns). The technique to avoid this is Curriculum Learning, which involves ordering data from simplest/cleanest to most complex, allowing model weights to configure themselves more robustly.
Question 3: In Knowledge Distillation, why are the Teacher model’s “Soft Targets” more useful than traditional Hard Labels?
Soft Targets provide a probability distribution across the entire vocabulary, not just a single “correct” answer. This distribution (“Dark Knowledge”) contains crucial information about how the Teacher perceives semantic relationships between words (e.g., knowing that a wrong answer is still semantically close to the right one), which helps the Student generalize much more effectively.
Question 4: What technical trade-off does “Activation Checkpointing” offer during training to avoid “Out Of Memory” (OOM) errors?
Activation Checkpointing saves massive amounts of VRAM (GPU memory) by removing intermediate activations calculated during the forward pass from memory. The trade-off is that these activations must be recalculated during the backward pass, which increases compute time by about 25%. We exchange compute time for memory space.
Question 5: Why is classic “Data Parallelism” (DP) no longer sufficient for today’s giant models, and why do we use FSDP?
Data Parallelism (DP) copies the entire model onto each GPU. For giant models (like a 70B), even a single model with its optimizer states exceeds the capacity of a high-end GPU (like an 80GB H100). FSDP (Fully Sharded Data Parallelism) solves this by sharding model weights, gradients, and optimizer states across all available GPUs, combining the memory efficiency of model parallelism with the simplicity of data parallelism management.