Finetuning Ninja: Week 1 - The Landscape
Lesson 1: Mapping Modern LLM Training
Welcome to the first week of our Finetuning Bootcamp! Here’s a small plot twist to kick things off: we’re not talking about finetuning today.
Before jumping into advanced techniques like SFT (Supervised Fine-Tuning) or LoRA, it’s crucial to build a solid mental map of what happens before finetuning even starts. This lesson lays the foundation of the Transformer architecture and pretraining, because understanding how models work under the hood is essential to mastering optimization techniques later on.
1. The Evolution: From RNNs to Attention

Today, nearly every state-of-the-art language model is built on top of the Transformer architecture. But the key innovation that makes them work—the attention mechanism—was not invented in the Transformer paper.
Long before that, deep learning relied on CNNs for vision and RNNs (especially LSTMs) for sequence modeling tasks like machine translation. The problem with RNNs? They struggled with long sequences because they had to compress an entire input sequence into a single, fixed-length vector.
Attention was introduced to solve this exact problem: instead of compressing everything, why not allow the model to look back at different parts of the input dynamically as needed?.

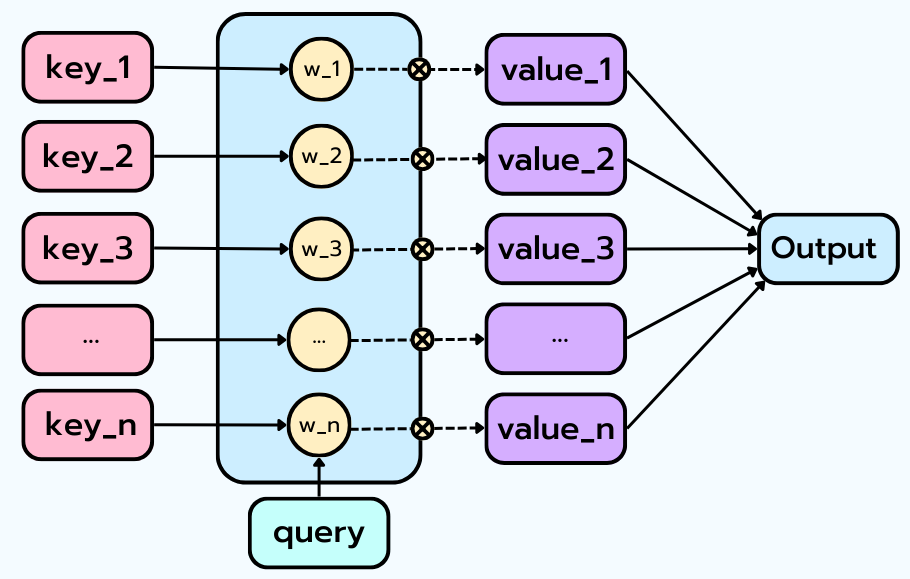
How does Attention work? At its core, attention is a weighted lookup mechanism that uses three elements: * A set of Keys (K) * A set of Values (V) * A Query (Q)
The mechanism compares the query to all keys, assigns a weight (importance score) to each one, and then produces a weighted sum of the values. Attention decides which pieces of information matter most in context and combines them dynamically.
2. The Core of the Transformer: Self-Attention and Multi-Head Attention
While attention allowed a decoder to look back at an encoder, Self-Attention takes the idea one step further: each token in a sequence attends to all the other tokens in the same sequence.
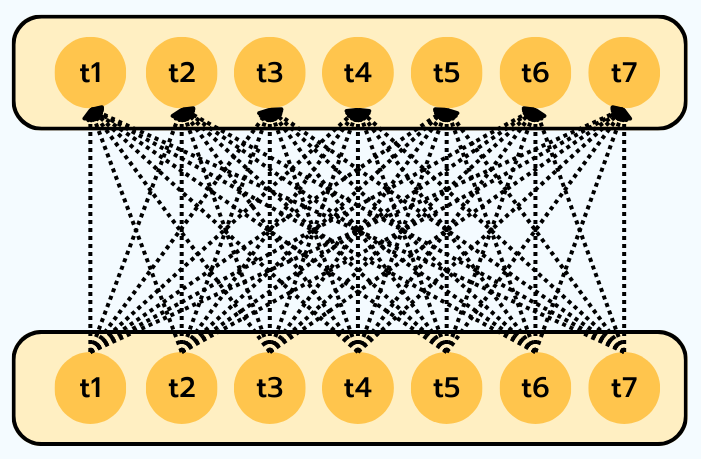
In self-attention, every token becomes a Query, a Key, and a Value. For example, when updating the representation of the word “sat”, the model can strongly attend to “cat” (who is sitting) and “mat” (where it happens), while ignoring less relevant function words like “the”.
To make this work, the Transformer architecture introduces specific components: 1. Positional Encodings: Attention itself has no notion of order. Positional information is injected via mathematical functions (sine and cosine at different frequencies) so the model can distinguish the first, next, or last token. 2. Scaled Dot-Product Attention: This is the mathematical implementation where Queries and Keys are compared using a dot product, normalized with a softmax function, and then used to compute a weighted sum of the Values. 3. Multi-Head Attention: Instead of forcing the model into one single view, it uses “multiple heads” working in parallel. Different heads can specialize in syntactic relationships, semantic similarity, or long-range dependencies, processing information from different angles at once.
3. The Three Transformer Architectures
While people group everything under “LLMs,” there are actually three different Transformer architectures, designed for different problems:
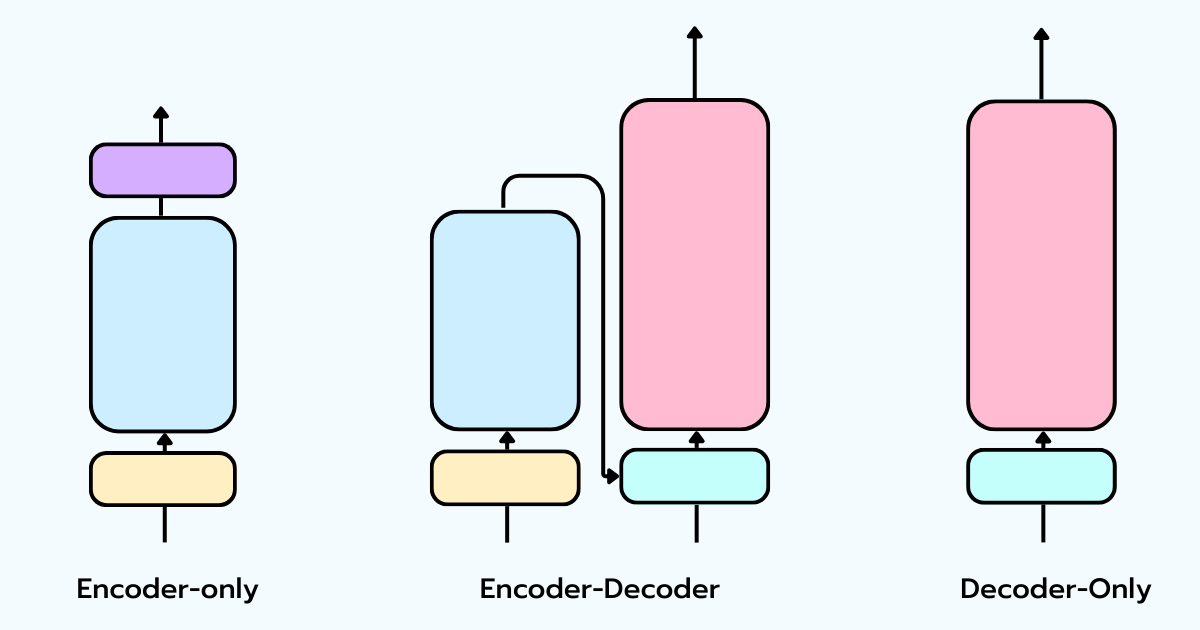
- Encoder-only (e.g., BERT): Designed to create rich representations. It uses bidirectional self-attention (tokens look forward and backward). It’s great for text understanding, classification, and retrieval, but it does not generate text.
- Encoder-Decoder (e.g., T5, BART): The original Transformer design. The encoder reads the sequence, and the decoder generates the output token by token using cross-attention. Ideal for sequence-to-sequence tasks like translation and summarization.
- Decoder-only (e.g., ChatGPT, Claude, Qwen): The engine behind modern LLMs. It removes the encoder entirely and relies on causal self-attention: each token can only attend to tokens that came before it. Its simple objective is to predict the next token.
The massive success of the decoder-only architecture is largely due to scaling laws. Empirical studies show that model performance improves smoothly and predictably as you increase model size (parameters), training data (tokens), and compute power.
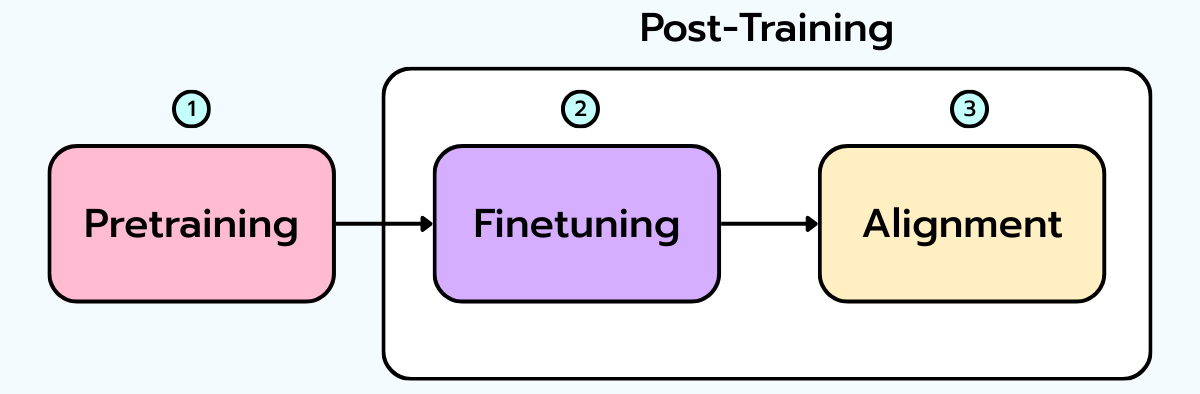
4. The LLM Training Pipeline and Pretraining
Since OpenAI’s InstructGPT in 2022, training a modern LLM typically follows a well-defined three-stage framework: 1. Pretraining (on large-scale raw text). 2. Supervised Fine-Tuning (SFT) (on high-quality, task-oriented examples). 3. RLHF - Reinforcement Learning from Human Feedback (Alignment).
Zooming in on Pretraining: This is where the vast majority of compute and data is spent. A decoder-only Transformer trains via self-supervised learning: the label to predict is simply the next token (Causal Language Modeling).
By consuming the internet (web pages, books, code), the model acquires grammar, syntax, code patterns, and common sense facts. This is the phase where it “learns the world”.
The result is a “Base Model” (Foundation Model). But beware: at this stage, the model is incredibly good at continuing text, but it cannot reliably follow instructions or behave safely. It’s a raw pattern-learning engine. Finetuning (SFT, LoRA) does not teach the model language from scratch; instead, it shapes and steers the raw capabilities learned during pretraining to make the model usable.
Continued Pretraining: What if you need highly specialized domain knowledge (legal, medical) or an underrepresented language? You can use Continued Pretraining. Instead of starting from scratch, you expose an existing base model to new data so it absorbs new patterns while retaining what it already knows.
🎯 Self-Assessment Quiz: Test Your Knowledge
Question 1: What fundamental problem with Recurrent Neural Networks (RNNs) was the original attention mechanism trying to solve?
Early recurrent architectures (like LSTM-based encoder-decoders) had to compress an entire input sequence into a single, fixed-length vector. This severely limited their performance on long sequences. Attention solved this by allowing the decoder to dynamically look back at all encoder states and access specific parts of the input exactly when needed, rather than relying on one compressed state.
Question 2: What is the main difference between classic attention and “Self-Attention”?
Classic attention was used to help one sequence (the decoder) attend to another sequence (the encoder). “Self-Attention” takes this further by having each token in a sequence attend to all the other tokens in the same sequence. As a result, the Queries (Q), Keys (K), and Values (V) all come from the same input source.
Question 3: Why does the Transformer architecture require Positional Encodings?
The attention mechanism inherently has no concept of sequence order. Unlike RNNs that process text sequentially, Transformers process tokens in parallel. Positional encodings (built using sine and cosine functions) artificially inject spatial information into the token representations so the model can distinguish between the “first”, “next”, and “last” elements.
Question 4: Which of the three Transformer architectures is used by models like ChatGPT and Claude, and what is its primary training objective?
These models are built on the Decoder-only architecture. Its primary training objective, utilizing causal self-attention (which prevents the model from peeking at future tokens), is remarkably simple: predict the next token (Causal Language Modeling).
Question 5: What is the purpose of Supervised Fine-Tuning (SFT) and RLHF if the model already learned language during pretraining?
Pretraining produces a “base model” that is excellent at generating text and possesses broad world knowledge, but it simply continues patterns and cannot reliably follow instructions or act safely. SFT and RLHF are used to shape and steer this raw intelligence. They teach the model how to structure answers, follow directions, and align with human expectations without having to rewrite its underlying understanding of language.
Question 6: What are the roles of the “Query”, “Key”, and “Value” components?
Think of it as a retrieval system. The Query is what you are looking for, the Key is the label of the available information, and the Value is the information itself. The attention score (Query x Key) determines how much “weight” is given to each “Value”.
Question 7: Why do modern models like Llama or GPT primarily use the “Decoder-only” architecture?
This architecture is easier to scale. It has proven incredibly effective for self-supervised learning on massive datasets, and it possesses emergent capabilities (reasoning, logic) that other architectures do not reach as easily.
Question 8: In which scenario would you use “Continued Pretraining” instead of simple Fine-tuning?
Continued pretraining is used when you want to inject massive knowledge from a very specific domain (e.g., complex medical law, rare programming languages, or underrepresented human languages) that the model has never seen, before teaching it to follow instructions in that domain.